MegaETH: Unveiling the First Real-Time Blockchain
MegaLabs
MegaETH is an EVM-compatible blockchain that brings Web2-level real-time performance to the crypto world for the first time. Our goal is to push the performance to hardware limits, bridging the gap between blockchains and traditional cloud computing servers.
MegaETH offers several distinguishing features, including high transaction throughput, abundant compute capacity, and, most uniquely, millisecond-level response times even under heavy load. With MegaETH, developers can build and compose the most demanding applications without bounds.
Why does the world need another blockchain?
The advancement of blockchain frameworks has significantly lowered the barriers to creating new chains. Consequently, a multitude of new chains has emerged recently. For instance, L2Beathas documented over 120 projects in the Layer-2 ecosystem. .
However, simply creating more chains does not solve the blockchain scalability issue, as each individual chain still imposes significant limitations on the dApps it hosts. For example, the table below shows the target gas per second and block time of major EVM chains today.
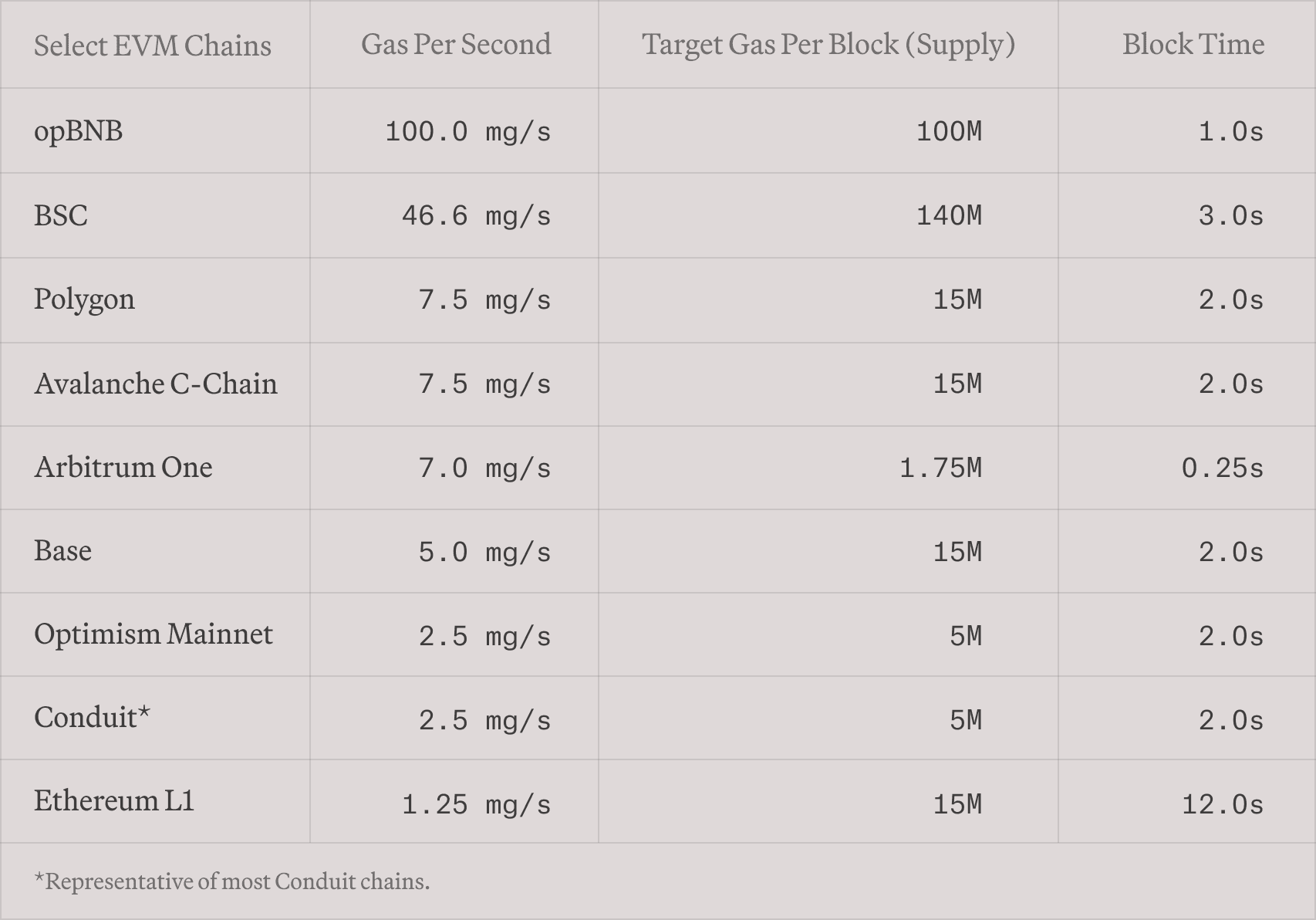
Table: Comparison of gas parameters across EVM chains in 2024 (source: Paradigm)
This table clearly shows that existing EVM chains face significant limitations in several aspects. First, all of them exhibit low transaction throughput. For example, although opBNB stands out with an exceptionally high gas rate of 100 MGas/s among the peers, it still pales in comparison to the capabilities of modern Web2 servers. For reference, 100 MGas/s translates to only 650 Uniswap swaps or 3,700 ERC-20 transfers per second. In contrast, modern database servers already exceed one million transactions per second in the TPC-C benchmark.
Second, sophisticated applications cannot be brought on-chain due to scarce compute capacity. For example, a simple EVM contract computing the n-th Fibonacci number consumes about 5.5 billion gas for n=10^8, which would take up the entire opBNB chain 55 seconds to compute at 100 MGas/s. In contrast, a similar program written in C can complete the same task in just 30 milliseconds, making it 1833 times faster already with a single CPU core! Now imagine the possibilities on a blockchain that harnesses multicore processing to unlock another 100 times more compute power.
Finally, applications that demand high update rates or fast feedback loops are not feasible with long block times. With the exception of Arbitrum One, all chains in the table update their states every second or more. However, sophisticated fully on-chain dApps such as autonomous world require high tick rates (e.g., block intervals of less than 100 milliseconds) to simulate real-time combat or physics. Additionally, on-chain high-frequency trading would not be possible unless orders can be placed or canceled within 10 milliseconds.
Fortunately, none of these limitations are insurmountable for EVM chains. With our technological advancements, it is time to build a real-time blockchain to unlock these potentials. More formally, a real-time blockchain is a blockchain that is capable of processing transactions as soon as they arrive and publishing the resulting updates in real-time. Further, it must support high transaction throughput and substantial compute capacity to maintain the real-time experience even during peak user demand.
Node specialization: a paradigm shift for performance-centric designs
Blockchain scalability has been an active area of research for many years. So, how can we suddenly achieve performance enhancements that surpass the current state of the art by orders of magnitude? The answer is surprisingly straightforward: by delegating security and censorship resistance to base layers like Ethereum and EigenDA, one can explore a vast design space for implementing aggressive performance optimizations.
To better understand this idea, let's start by examining how blockchains function today. Every blockchain comprises two fundamental components: consensus and execution. Consensus determines the order of user transactions, while execution processes these transactions in the established order to update the blockchain state.
In most L1 blockchains, each node performs identical tasks without specialization. Every node participates in a distributed protocol to achieve consensus and then executes each transaction locally. This setup imposes a fundamental trade-off between performance and decentralization. Every L1 must decide to what extent they can increase the hardware requirements for regular users to run a node, without undermining the fundamental properties of a blockchain such as security and censorship resistance.
It's crucial for blockchain decentralization for regular users to be able to run a node.
However, there is no definitive answer to what hardware requirements are acceptable for full nodes. Different L1s position themselves quite differently along the spectrum of performance versus decentralization. For example, the following table shows the recommended hardware configurations of several L1s.
| CPU | Memory | Network | Storage | |
|---|---|---|---|---|
| Ethereum | 2 cores | 4-8 GB | 25 Mbps | SSD |
| Solana | 12 cores | 256 GB | 1-10 Gbps | SSD |
| Aptos | 32 cores | 64 GB | 1 Gbps | SSD |
In contrast, L2 represents a paradigm shift in blockchain design, eliminating the need for a one-size-fits-all hardware requirement for its nodes. This is because an L2 blockchain is inherently heterogeneous: different nodes are specialized to perform specific tasks more efficiently. For example, common L2s utilize a special sequencer node to determine the order of transactions. In addition, prover nodes in ZK-Rollups often rely on specialized accelerators such as GPU and FPGA to reduce the cost of proof generation. MegaETH takes node specialization to the next level by introducing a new class of nodes called replica nodes, which completely forego transaction execution, distinguishing them from traditional full nodes.
As a result, there are four major roles in MegaETH: sequencers, provers, full nodes, and replica nodes. Sequencer nodes are responsible for ordering and executing user transactions. However, MegaETH has only one active sequencer at any given time, eliminating the consensus overhead during normal execution. Replica nodes receive state diffs from this sequencer via a p2p network and apply the diffs directly to update the local states. Notably, they don't re-execute the transactions; instead, they validate blocks indirectly using proofs provided by the provers. Full nodes operate as usual: they re-execute every transaction to validate blocks. This is essential for power users, such as bridge operators and market makers, to achive fast finality, albeit with higher hardware requirements to keep up with the sequencer. Finally, the provers, using the stateless validation scheme, validate blocks asynchronously and out-of-order.
The figure below illustrates the basic architecture of MegaETH and the interaction between its major components. Note that EigenDA is an external component built on EigenLayer.
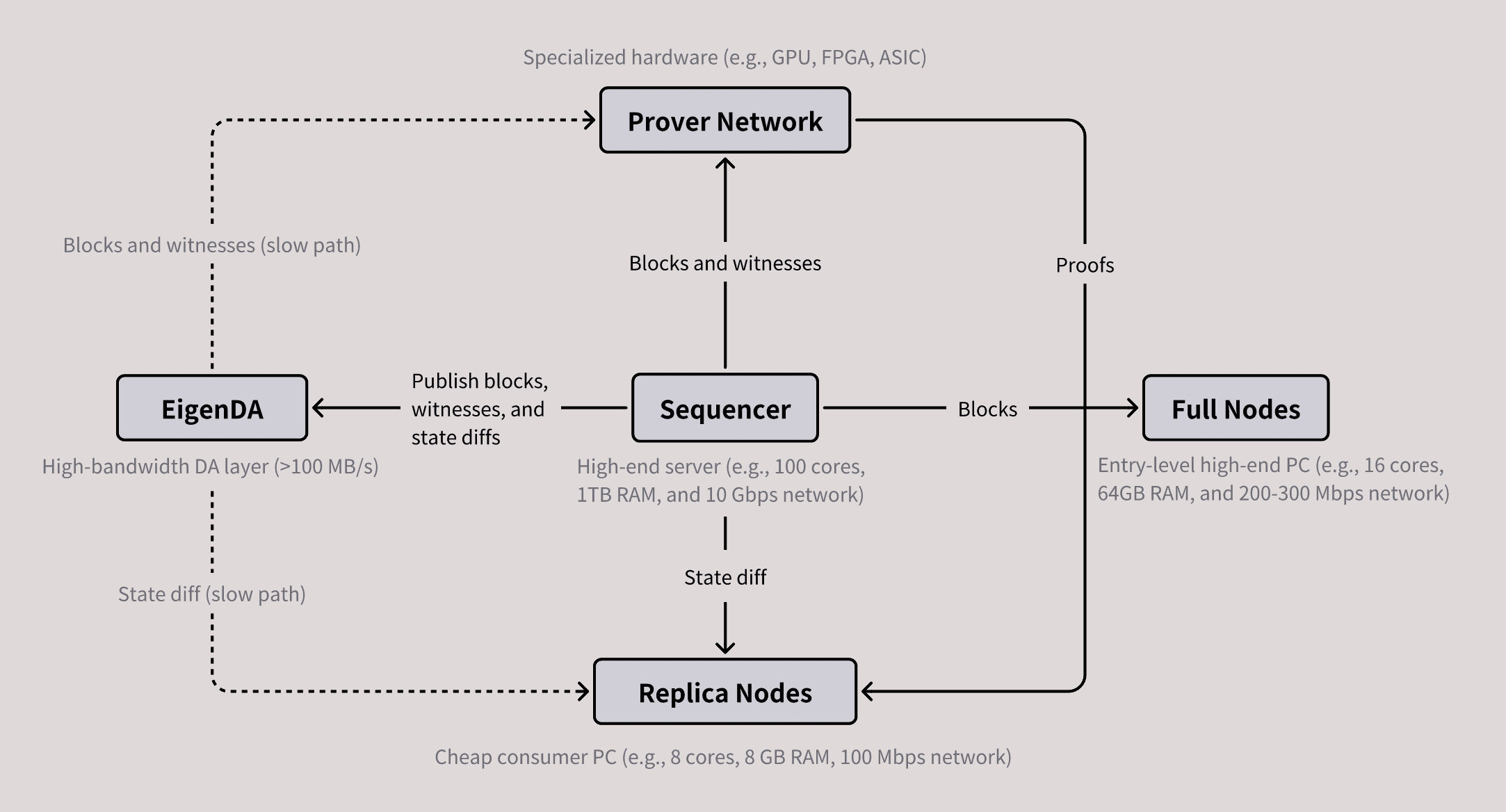
Figure: Major components of MegaETH and their interaction.
A key advantage of node specialization is the ability to set the hardware requirements for each type of node independently. For example, since sequencer nodes handle the heavy lifting of execution, it is desirable to run them on high-end servers to enhance performance. In contrast, the hardware requirements for replica nodes can remain low because verifying proofs is computationally inexpensive. Additionally, while full nodes still perform execution, they can leverage the auxiliary information generated by sequencers to re-execute transactions more efficiently. The implication of this setup is profound: as outlined in Vitalik's Endgame post, node specialization ensures trustless and highly decentralized block validation, even though block production becomes more centralized.
This table outlines the projected hardware requirements for each type of node in MegaETH:
| CPU | Memory | Network | Storage | Example VM (Price/h) | |
|---|---|---|---|---|---|
| Sequencer | 100 cores | 1-4 TB | 10 Gbps | SSD | AWS r6a.48xlarge ($10) |
| Prover (OP) | 1 core | 0.5 GB | Slow | None | AWS t4g.nano ($0.004) |
| Replica node | 4-8 cores | 16 GB | 100 Mbps | SSD | AWS Im4gn.xlarge ($0.4) |
| Full node | 16 cores | 64 GB | 200 Mbps | SSD | AWS Im4gn.4xlarge ($1.6) |
We omit ZK prover nodes from the table as their hardware requirements largely depend on the proof stack and can vary significantly across different providers. The hourly costs of various VM instances are sourced from instance-pricing.com. Notably, node specialization allows us to have sequencer nodes that are 20 times more expensive (and 5-10 times more performant) than the average Solana validator, while keeping the costs of full nodes comparable to those of Ethereum L1 nodes.
Engineering a real-time blockchain
The concept of node specialization is elegant and powerful. Naturally, this raises the question: is the secret behind MegaETH merely a beefy centralized sequencer? The answer is no.
While drawing an analogy to centralized servers can be a useful mental model to understand the potential of MegaETH, it significantly underestimates the research and engineering complexities behind the stage. Creating a real-time blockchain involves much more than taking an off-the-shelf Ethereum execution client and ramping up the hardware of the sequencers.
For instance, our performance experiments show that even with a powerful server equipped with 512GB RAM, Reth can only achieve about 1000 TPS, which translates to roughly 100 MGas/s, in a live sync setup on recent Ethereum blocks. In this particular experiment, Reth's performance is bottlenecked by the overhead of updating the Merkle Patricia Trie (MPT) in each block, which is almost 10x more computationally expensive than executing the transactions. For more details, we refer readers to our presentation in EthDenver'24: Understanding Ethereum Execution Client Performance.
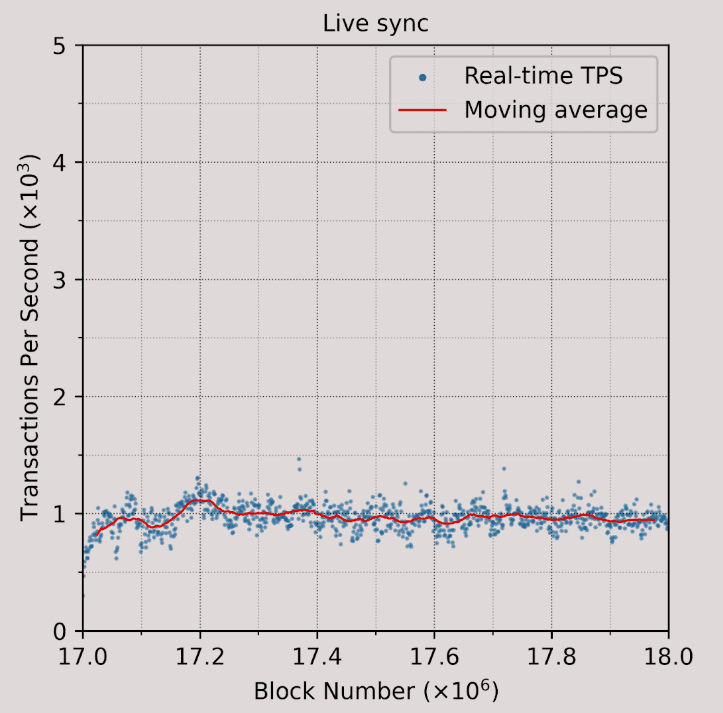
Figure: Live sync performance of Reth
In summary, while the node specialization unlocks significant opportunities in performance improvements, designing and implementing a hyper-optimized blockchain remains an unsolved challenge.
Our design philosophy
Like any complex computer system, a blockchain has many potential bottlenecks across multiple interacting components. Addressing any bottleneck in isolation rarely results in significant end-to-end performance improvements because either (1) it's not yet the most critical limiting factor, or (2) the most critical bottleneck simply shifts to another component. Time and again, we have seen too many projects focus on optimizing specific components. While they may demonstrate impressive speedups in isolated microbenchmarks, these results often fail to translate into end-to-end performance gains that benefit the end users.
At MegaETH, we decided to apply a more holistic and principled approach in our R &D process from the beginning. Our design philosophy can be summarized as follows.
First, we always "measure, then build." That is, we always start by conducting deep performance measurements to identify the real problems of existing systems. Based on these insights, we then design new techniques to address all the problems simultaneously.
Second, we strive to design the system to reach hardware limits. Instead of making incremental improvements over existing systems, we prefer clean-slate designs that approach the theoretical upper bounds. Our goal is to leave little room for further performance improvements to the crypto infrastructure, so the industry can finally divert resources to other challenges hindering adoption.
Below, we present a walkthrough of the major challenges in designing and implementing a high-performance real-time blockchain.
Transaction execution
The figure below illustrates the journey of a user transaction through the system and will serve as a reference for explaining the technical challenges discussed later.
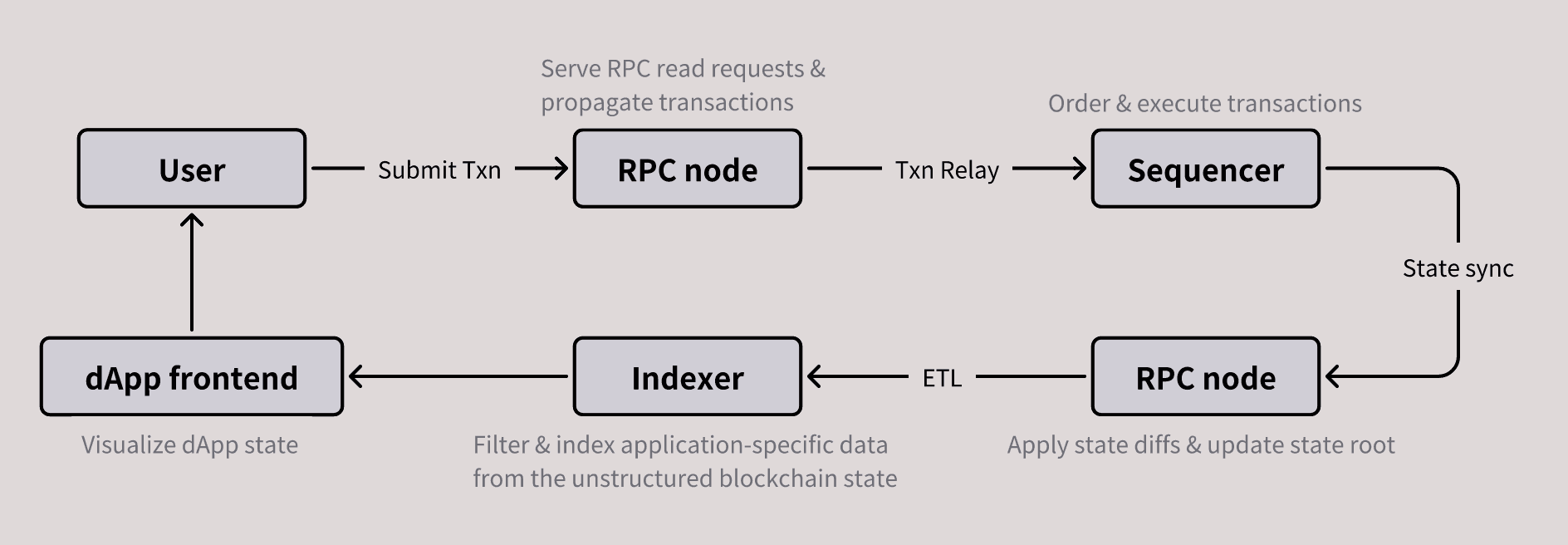
Figure: Journey of a user transaction (RPC nodes can be full or replica nodes).
We will start with the sequencer because it's the component most familiar to many people. The sequencer is responsible for ordering and executing transactions. The EVM is often blamed for the relatively low execution performance, which has contributed to numerous efforts to replace the EVM with other virtual machines in Ethereum L2s.
However, this stereotype is simply not true. Our performance measurements show that revm can already achieve approximately 14,000 TPS on recent Ethereum blocks in a historical sync setup. The machine configuration is the same as the live sync experiment presented earlier.
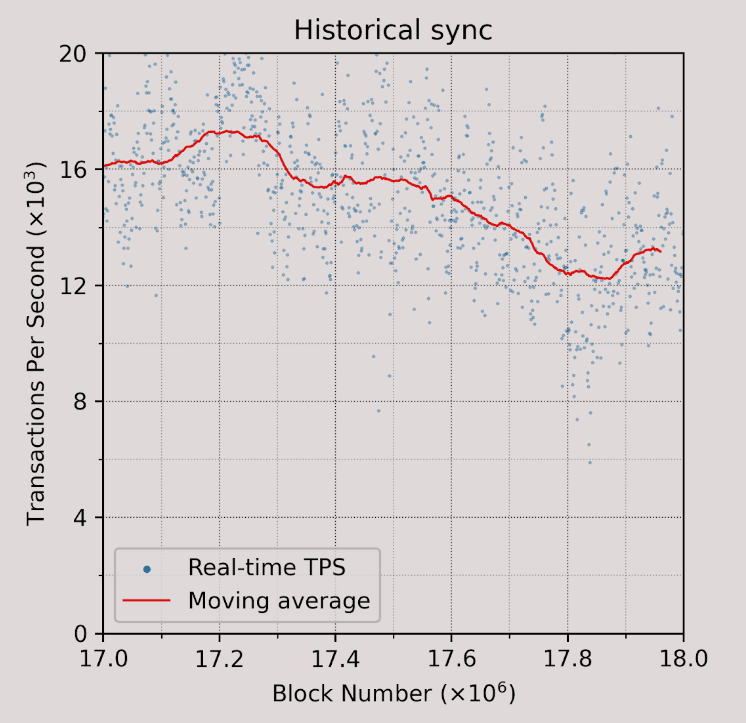
Figure: Historical sync performance of Reth.
While 14,000 TPS is more than enough for most L2s, it falls short for a real-time blockchain like MegaETH. Traditional EVM implementations face three major inefficiencies: 1) high state access latency, 2) lack of parallel execution, and 3) interpreter overhead. Thanks to node specialization, our sequencer nodes are equipped with abundant RAM to hold the entire blockchain state, which is currently around 100GB for Ethereum. This setup significantly accelerates state access by eliminating SSD read latency. For example, in our historical sync experiment above, the sload operation accounts for only 8.8% of the runtime. As a result, we will focus on the other two challenges below.
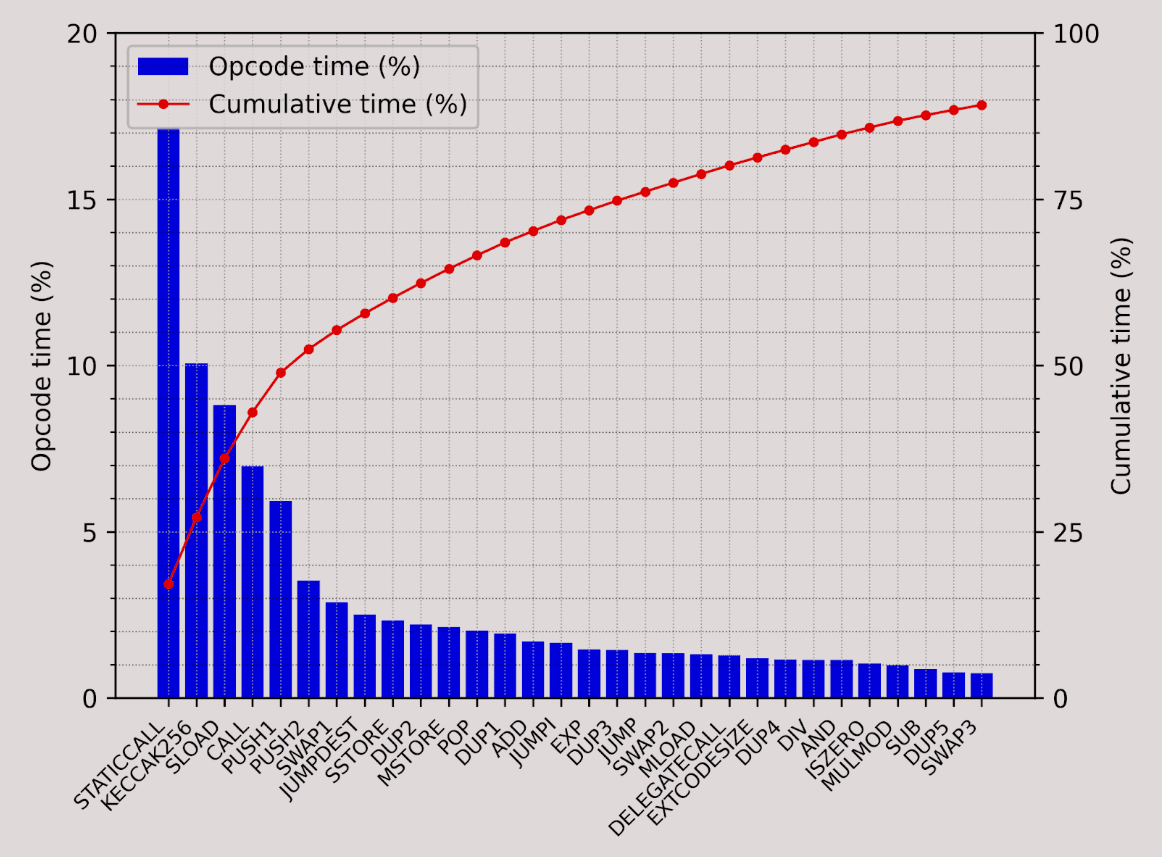
Figure: Top 30 most time-consuming opcodes.
Parallel EVM has become a hot topic recently, with many teams focusing on porting the Block-STM algorithm, originally implemented for MoveVM, to EVM. While it’s safe to say that parallel EVM is a solved problem, there is a catch: the actual speedup achievable in production is inherently limited by the parallelism available in the workloads.
Unfortunately, our measurements indicate that the median parallelism in recent Ethereum blocks is less than 2. Even if we artificially merge blocks into large batches, the median parallelism only increases to 2.75. By inspecting the raw experiment data, it is clear that long dependency chains are prevalent in today's Ethereum workloads. Without further techniques to resolve the conflicts and increase parallelism, the benefits of parallel EVM will remain relatively limited.
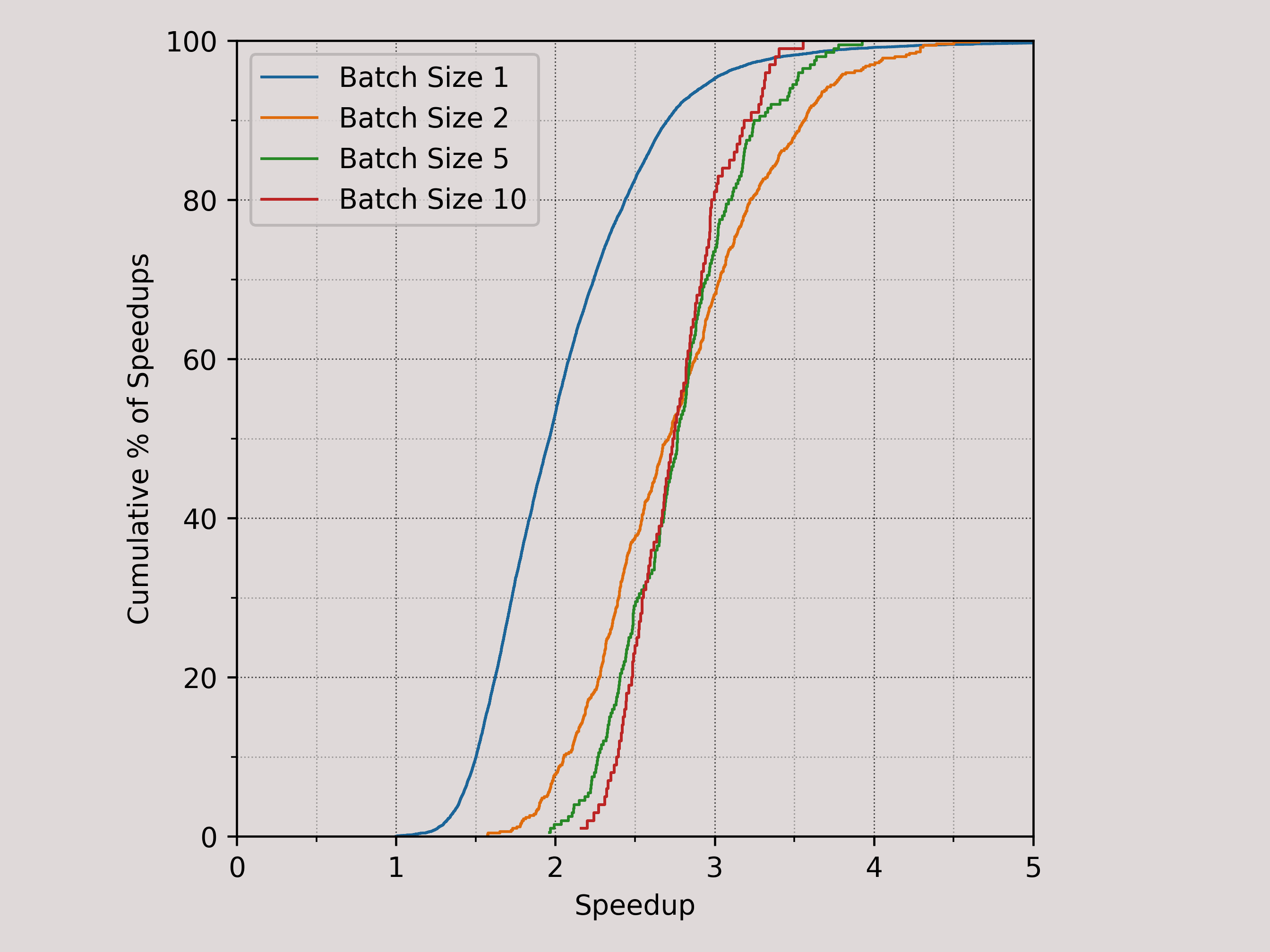
Figure: Parallelism available from block 20000000 to 20010000
As discussed in the Fibonacci example earlier, even a relatively fast EVM interpreter like revm is still 1-2 orders of magnitude slower than native execution. Echoing this performance gap, there has been renewed interest in using AOT/JIT compilation to accelerate single-thread EVM execution, with competing efforts from multiple teams such as revmc, evm-mlir, and IL-EVM.
While these projects have shown promising results on several compute-intensive contracts, their speedups are quite limited in a production environment. One reason is that most contracts today are not very compute-intensive. For instance, we profiled the time spent on each opcode during historical sync and discovered that approximately 50% of the time in revm is spent on "host" and "system" opcodes, such as keccak256, sload, and sstore, which are already implemented in Rust. Consequently, these opcodes cannot benefit from compilation, limiting the maximum speedup in production to 2x.
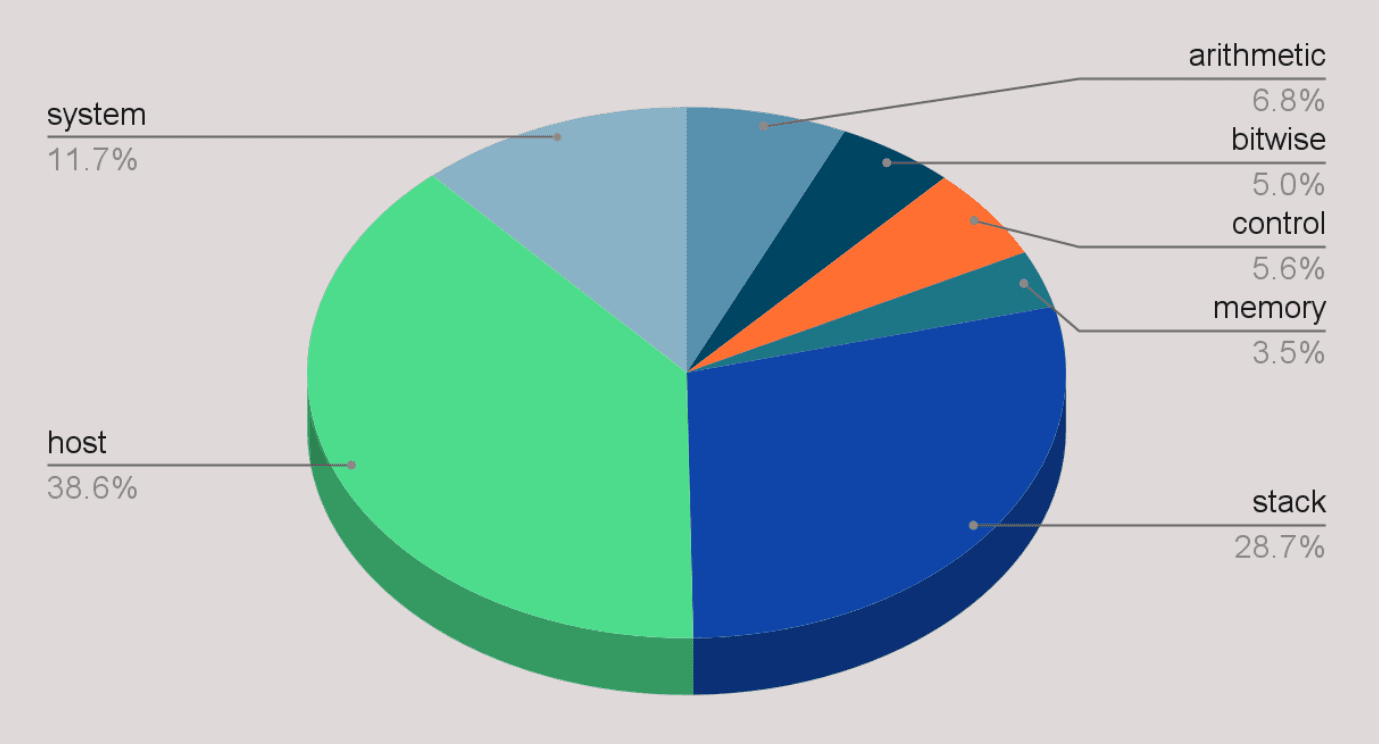
Figure: Time breakdown by opcode category in historical sync.
So far, we have only discussed challenges that are generic to all high-performance EVM chains. The requirements of real-time blockchains introduce at least two additional challenges. First, we need to produce blocks consistently at high frequency, such as every 10 milliseconds. Second, our parallel execution engine must support transaction priorities, allowing critical transactions to be processed without queuing delays, even during peak congestion times. Thus, despite being a good general solution, Block-STM is not suitable in our low-latency environment.
State synchronization
State sync is the process that brings full nodes up to speed with the sequencer. It is one of the most challenging aspects in high-performance blockchain design, yet it is often overlooked.
To understand why state sync is challenging, consider simple transactions like ERC-20 transfers. Let's do a back-of-the-envelope calculation to determine the required bandwidth to sync 100,000 ERC-20 transfers per second. Each ERC-20 transfer modifies three values: the sender's balance (20 bytes for the address + 32 bytes for the value) and two storage slots (64 bytes each) under the ERC-20 contract (20 bytes for the address). Therefore, a straightforward way to encode the state diff costs about 200 bytes. At 100,000 transfers per second, this translates to 152.6 Mbps of bandwidth consumption, which already exceeds our bandwidth budgets. Comparatively, this is even more expensive than transmitting the 177-byte raw transaction data directly.
More complex transactions produce larger state diffs. For example, a Uniswap swap modifies 8 storage slots across three contracts, in addition to the sender's balance: i.e., 64B * 8 + 20B * 3 + 52B = 624B. At 100,000 swaps per second, the bandwidth consumption is now 476.1Mbps!
Moreover, just because a full node has a 100Mbps network connection doesn't mean it can sync at 100% network utilization. There are several reasons for this. First, internet providers often overstate the actual sustainable bandwidth. Second, applications on the same node must share the connection. Third, sufficient headroom must be reserved for new full nodes to bootstrap and join the network. If full nodes always run at 100% network utilization, newly joined nodes would never be able to catch up to the tip. Finally, peer-to-peer network protocols inevitably introduce their own overheads.
So, how much bandwidth can we comfortably allocate toward state sync? Suppose the average sustainable bandwidth is 75Mbps, and we set aside two-thirds of it for other applications and bootstrapping new nodes. That leaves us with 25Mbps. In that case, syncing 100,000 Uniswap swaps per second would require a 19x compression rate of state diffs!

Forgot state sync in your whitepaper?
Updating the state root
Most blockchains, including Ethereum, use a tree-like authenticated data structure such as MPT to commit their states after each block. The commitment, known as the state root, is essential for serving storage proofs to light clients. Consequently, even with node specialization, full nodes are still required to maintain the state root, just like the sequencer nodes.
As discussed earlier, updating the state root in Reth is currently almost 10x more expensive than executing the transactions, since this process is extremely IO intensive. For example, the figure below illustrates the IO pattern involved in updating a leaf node in a binary MPT.
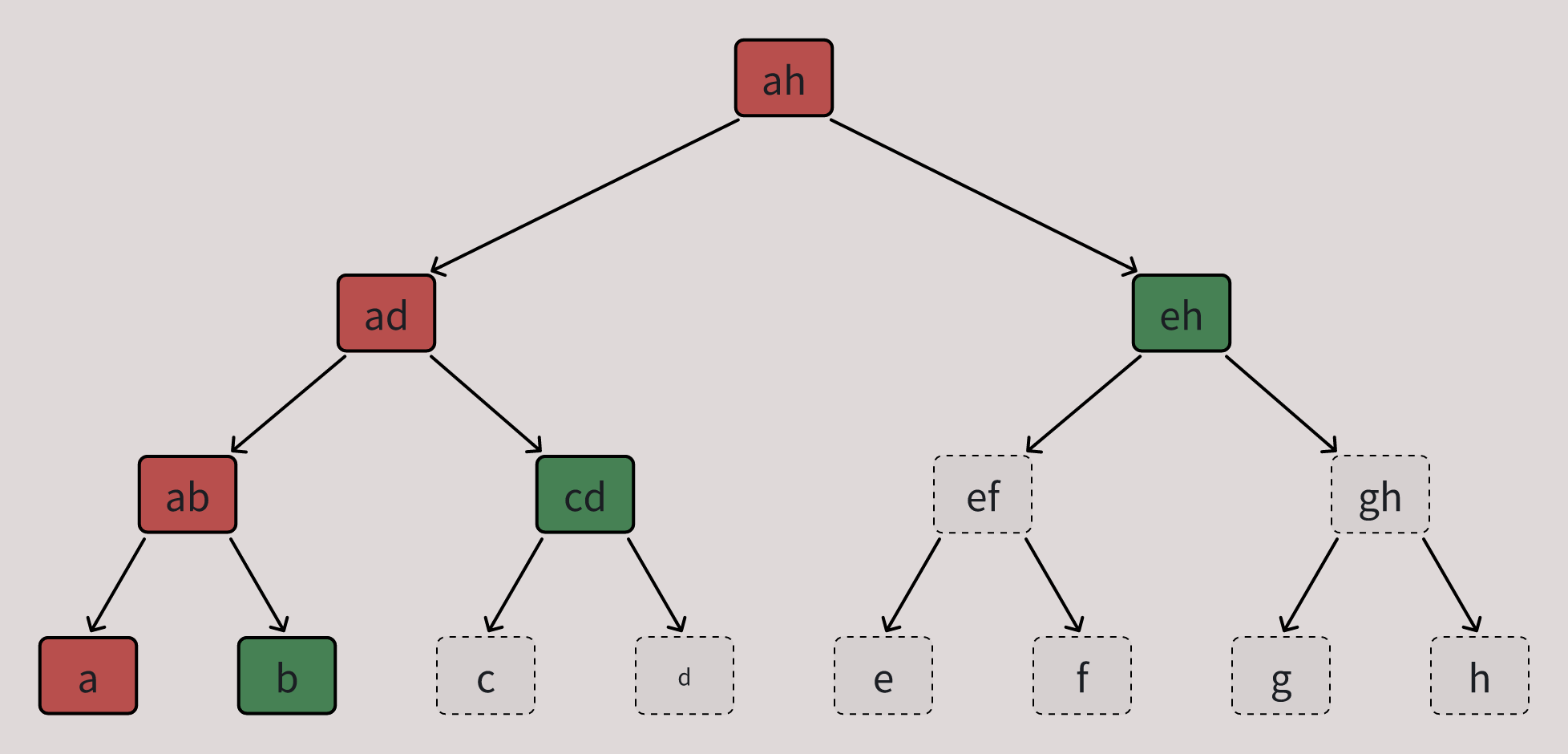
Figure: Read (green) and written (red) nodes when updating the state root of a binary MPT.
In MPT, each leaf stores a key-value pair that is part of the blockchain state, while each internal node stores an intermediate hash that commits to its underlying subtree and contains pointers to its child nodes. To update the state root after modifying a leaf, all internal nodes along the path from the root to that leaf must also be updated, which further requires reading their child nodes to recompute the hashes. For instance, updating leaf a in the figure above involves reading 3 nodes and updating 4 nodes in total. Note that an internal node must be read before it can be updated; otherwise, it is impossible to determine how to fetch its child nodes.
In general, updating a single key-value pair in a k-ary MPT with n leaves requires reading and writing O(k \log_k n) and O(\log_k n) nodes, respectively. For a binary MPT with 16 billion keys (i.e., 1 TB of blockchain state), this translates to approximately 68 read operations and 34 write operations. Fortunately, we can typically cache the first 24 levels of a binary MPT, so only the last 20 read and 10 write operations may incur random disk I/Os.
To better understand this challenge, let's revisit the example of 100,000 ERC-20 transfers per second. Since each ERC-20 transfer modifies three values, the state trie must support updating 300,000 keys per second. For a naive binary MPT, this would translate to approximately 6 million non-cached database reads. Even if we assume that each of these database reads can be served with a single disk I/O, 6 million IOPS far exceed the capabilities of any consumer SSD today — and this calculation doesn't even account for the write operations.
A common optimization strategy to reduce disk I/O is to group multiple trie nodes in a subtree together and store them in one 4KB disk page. For instance, NOMT fits each rootless binary subtree of depth 6 into a disk page. Ideally, this would reduce the number of non-cached database reads per updated key from 20 to 2, resulting in approximately 600,000 IOPS. However, it is important to note that the gap between an optimistic back-of-the-envelope calculation and the performance of an actual implementation can be substantial due to software overheads. According to Thrum's benchmark, an NOMT with 134 million keys can currently handle up to 50,000 leaf updates per second. While this represents a significant improvement over existing state trie implementations, it is still 6 times below our desired throughput, while operating on a blockchain state that is 128 times smaller than the example above.
Block gas limit
So far, we have discussed the challenges in speeding up various tasks performed by blockchain nodes. However, there is a catch: even if someone manages to develop a brilliant technique that speeds up a specific task by 10x most of the time, it does not necessarily mean the blockchain can run any faster.
The reason is that the maximum speed of a blockchain is limited by an artificial cap known as the block gas limit, which is baked into the consensus. The block gas limit defines the maximum amount of gas that can be consumed within a single block. Along with block time, the block gas limit acts as a throttling mechanism to ensure that any node in the system can reliably keep up with the rest of the network, provided it meets the minimum hardware requirements.
The block gas limit is essential for ensuring the security and reliability of a blockchain. A rule of thumb in setting the block gas limit is that it must ensure that any block within this limit can be reliably processed within the block time. Failing to meet this criterion would expose the network to vulnerabilities from malicious attackers. In other words, the block gas limit must be chosen conservatively to account for worst-case scenarios.
For example, recall that the practical speedup of a parallel EVM is highly workload-dependent. While it is possible to achieve an average speedup of 2x on historical workloads, a significant portion of blocks contain long dependency chains and therefore experience minimal speedups. As a result, without some multidimensional gas pricing mechanism, such as Solana's local fee market, that can price accesses to contended hotspot states more expensively, it is not feasible to raise the block gas limit based on the average speedup achieved by a parallel EVM, let alone its maximum speedup.
Similarly, the speedups of JIT-compiled contracts largely depend on the nature of the contracts. While compute-intensive contracts may see 1-2 orders of magnitude speedups, most contracts today experience only moderate improvements. Moreover, JIT compilation introduces overheads that are not captured by the current gas model. For example, compilation itself consumes CPU cycles, keeping the resulting native code takes up memory or disk space, etc. Thus, before the gas model is reworked to (1) account for the compilation overheads, and (2) properly reprice the opcodes that do not benefit from compilation, we cannot aggressively raise the block gas limit to enable compute-intensive applications.
Supporting infrastructure
Finally, users don't interact directly with the sequencer nodes, and most do not run full nodes at home. Instead, users submit transactions to third-party RPC nodes and rely on web frontends of dApps or blockchain explorers, such as etherscan.io, to confirm the transaction results.
Thus, the actual user experience of a blockchain largely depend on its supporting infrastructure, such as RPC nodes and indexers. No matter how fast a real-time blockchain runs, it won't matter if RPC nodes cannot efficiently handle large volumes of read requests during peak times, quickly propagate transactions to sequencer nodes, or if indexers cannot update application views fast enough to keep up with the chain.
Scaling blockchain with a principled approach
We hope it's now clear that blockchains are truly complex systems with many moving parts, and improving blockchain performance requires more than isolated techniques such as parallel EVM or JIT compilation. All successful high-performance L1 blockchains, such as Solana and Aptos, have undertaken impressive engineering efforts across nearly every aspect of their systems.
That is why MegaETH is committed to a holistic and principled R &D approach from the start. By conducting deep performance analysis early on, we ensure that we always focus on solving problems that will bring real gains to users. Throughout the journey, we are excited to realize that, for all the challenges discussed earlier, we have something cool to offer. While the specific solutions are outside the scope of this post, we look forward to covering them in more detail in the future.
Bringing real-time performance to billions of users
Real-time blockchains will blur the line between Web2 servers and blockchains. With MegaETH, end users will experience unprecedented real-time performance, while developers will be able to explore their most ambitious ideas without limitations. After a decade of experimentation, we can finally approach Web2-scale applications on-chain.
We are deeply grateful to our supporters so far and incredibly excited to share more about what have to offer. Till next time.